Exchange Replication over a Split Network
Let’s start off by explaining what I mean by Exchange replication over a split network. I am talking about a DAG split over two Data Centres (and AD Sites) with separate links for replication and for user/MAPI traffic. Although let’s also quickly add that Microsoft now recommends that you only do this when you have a specific requirement to do so. The recommended best practice is keep it simple. If you can satisfy your business requirements with a single WAN connection in each site, then use that model.
The Problem
A typical representation of a 6 node DAG (ignoring the File Share Witness since we’re talking about replication, although interestingly Microsoft’s recommendation for the File Share Witness is to place it into a third site for best Exchange availability and failover). We’re only showing a high level network design here, ignoring any local redundancy, just to keep the image understandable and to focus on the problem at hand.
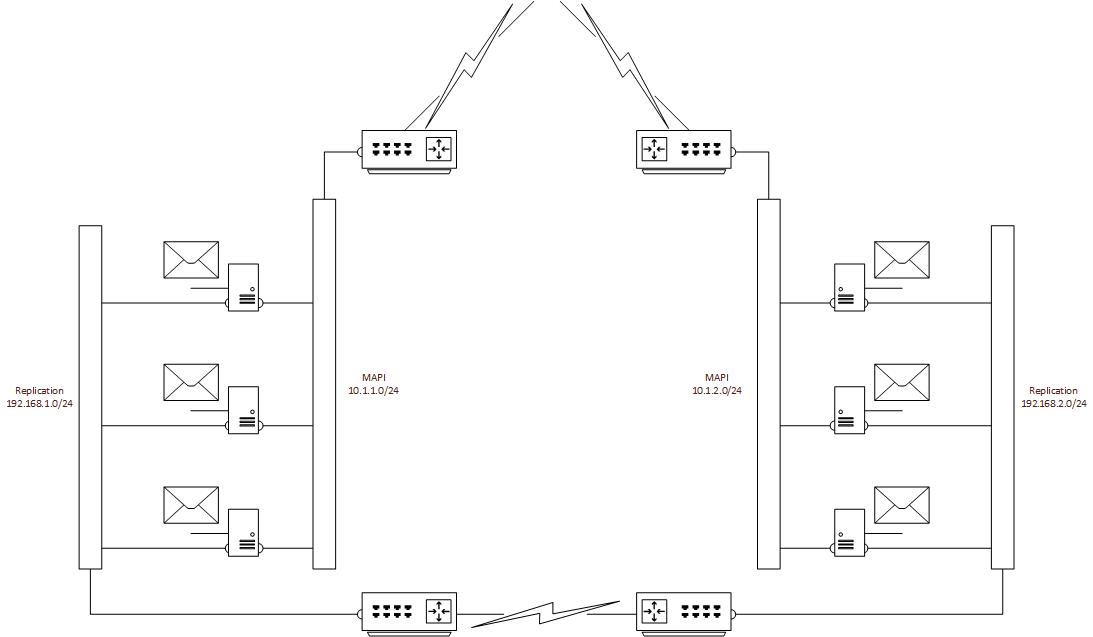
So the Exchange servers have multiple NICs, with one dedicated to replication traffic on 192.168.x.x and another (or a team) dedicated to user or MAPI traffic on 10.1.x.x. So you may think what is difficult about that? The devil is in the detail… Exchange replication consists of two parts.
- Log Shipping
- Content Indexing
Log Shipping
Exchange log shipping is done over a static tcp port (by default 64327). This is the process of simply taking any closed logs from the active server and moving it to the standby servers, and the replaying that log so that the passive mailbox databases are up to date. This is cluster aware and will honor the cluster network settings for which NICs should be used for replication and which should not. NOTE the word should here, since failures will cause this to change. Exchange may in some circumstances use the MAPI NICs.
Content Indexing
Content indexing is done using RPC/MAPI as well as SMB. This is the process of bringing any indexes (like Full Text) up to date. This runs on the active server as well as all of the passive servers, but the kicker here is that all of them refer to the active database’s server using DNS. This is NOT cluster aware, and will always using the MAPI NICs.
Now the most damaging piece here is that the log shipping component is the least network bandwidth hungry, about 40% of the traffic in the Exchange Calculator is log shipping and the balance is content indexing. The other thing with content indexing is that it is Kerberos encrypted, meaning if you have 2 or more remote copies and you want to leverage a WAN Optimization tool, then this tool cannot optimize the content indexing traffic, whereas it can deduplicate and compress the log shipping traffic (generally by more than the 30% saving that Exchange can give)
The solution
OK, so we understand the problem now so what are some solutions?
Solution 1: Wait for Microsoft to change the way it does content indexing
The best option I think, is for Microsoft to change the way it does content indexing. The passive servers have a copy of the data, is it not possible to add a semi-mounted state so that the data can be read locally for content indexing. I’m sure this isn’t a trivial task, but it would remove enormous quantities of traffic from the WAN, it would also avoid the pesky issues with Content Indexing not going back to a healthy state automatically and having to suspend/resume copies. OK almost ranting now perhaps that’s another blog post in the making.
Now the problem here is that Microsoft aren’t likely to do this…
[Edit: 10-Nov-2016 Exchange 2013 CU3 and Exchange 2016 actually do now try to use the passive mailbox copy where possible to do the content indexing. If this fails for any reason then Exchange will revert back to using the active copy]
Solution 2: Simplify the network by having only a single WAN connection at each site
Ok Microsoft’s option, remove the complication, scale the single WAN connection at each site for both MAPI, user and replication traffic, and ensure the uptime of the link (NOTE we’re talking a single logical WAN connection, in most environments this will be multiple links with automatic load balancing or failover)
This is a great option if you’re starting out with a design, but what if you’ve already bought the links, got them up and running and are wondering why the Exchange replication link is so lightly used yet the production links are maxed out?
Solution 3: Use DNS hosts files
A quick and dirty option is to place hosts files on all of the Exchange servers to force local resolution of the servers in the DAG to always be to the IP of the replication NIC.
This is fine for normal running, but what if the replication NIC fails? Log shipping would flip to use the production NICs, and content indexing would simply stop, as would any powershell that relies on a connection to the remote server, like stop-DatabaseAvailabilityGroup, etc.
Solution 4: Add further complication to the network
A more complete solution is to push the complication onto the network. As long as we ensure that in each site any traffic that is destined for the other site’s Exchange servers is routed down to the replication link then that will keep the WAN traffic split. Now this does mean that if the replication WAN link fails then all Exchange replication will stall. This can be an acceptable business risk, or you may already have multiple dedicated physical replication links with failover at the network layer.

In the diagram above we’ve added two network links and four static routes to ensure that servers on the left if they need to use the production (10.1.2.0/24) IPs to talk to the servers on the right, then the traffic will go from the servers production NIC onto the MAPI router at the top, gets routed down to the replication routers at the bottom, across the replication WAN link, up to the MAPI router at the top and finally into the production NIC of the destination server. Phew!
Now you may say, what about end user traffic. A very good question, luckily normally we’re using a hardware load balancer which uses a load balanced name which users access, so users don’t access the server IPs directly themselves or if they do then the WAN will have ensured that this routes into the correct site to start with.
One thing this does affect is proxying, if you’ve set up Exchange to do inter-site proxying then that traffic will now go over the replication link, this type of inter site proxying should become less prevalent with active/active configurations where the user would get redirected rather than proxied, but is an issue to point out.
Conclusion
Basically if you want to avoid network induced headaches if not migraines, then consider sizing the production WAN links and network gear to deal with both user traffic and replication traffic. This keeps all the traffic on one set of links with predictable routes.
Oh yeah and don’t allow the link to fill up, I’ve seen an Exchange 2010 DAG become completely unstable with failovers happening seemingly randomly because of traffic shaping restricting Exchange replication (and therefore cluster heartbeat traffic)
Bonus Gotcha
One final gotcha to bear in mind… Exchange doesn’t like empty databases with multiple copies. What happens is that content indexing goes nuts trying to set up the index and it generates enormous amounts of network traffic. So far the official answer from Microsoft has been “there should be no reason to have empty databases for any length of time, create a mailbox in each database as soon as possible” Not quite the answer I had hoped for, but creating a mailbox in each database did indeed stop the spurious replication traffic…
